Export Splunk Data for Self-Service Analytics

It’s Not a SPLing Contest
Do most of your staff know how to write SPL? Of course, not; some users get it, but others either don’t know, can’t be bothered to learn, or just plain don’t have the time. So, how do you get the most value out of the data you have in Splunk? One option is to teach users to use Splunk’s Pivot, Table Views, and the Datasets Add-On, but none of them come close to the drag-and-drop functionality of Business Intelligence (BI) solutions like Microsoft Power BI, Tableau, QlikView, et al. The options you’re left with are:
- Putting all users through Splunk training
- Centralizing the development of use cases
- Distributing the data to other platforms your teams know how to use
- Skipping Splunk altogether for specific use cases
Let’s talk about options 3 and 4 and what solutions are available.
Splunk ODBC
One option for connecting your Splunk data to applications that users may already know how to use is the Splunk ODBC driver [docs]. Installing the driver locally on a Windows PC allows you to connect ODBC client applications to Splunk saved searches, which are presented to clients as database tables using fixed field lists and time windows.
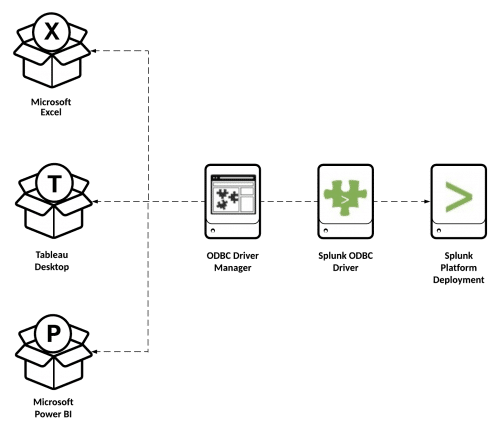
There are drawbacks when offloading the number-crunching to third-party applications, including:
- Saved searches must either cover every use case or present all data to be processed client-side.
- Indexers end up doing more work but less filtering, which results in slow queries and poor scaling.
- Server-side parameterization and filter options are very limited.
- Search results are limited to 50,000 records by default.
With Splunk ODBC, you have no control over the time window or server-side data aggregation when doing ODBC queries from your own application. These issues mitigate the major benefits of a time series data store and horizontally scaling, which cripples the value of Splunk for these use cases. Unless you’re doing static reporting or have a 1:1 mapping of application reports to saved searches, users end up with a slow and unresponsive experience.
Splunk REST API Integrations
Some applications like Tableau allow you to integrate with Splunk with a middleware layer that connects to the Splunk API, working in place of the ODBC adapter. Splunk’s first-party Tableau solution is the Tableau Web Data Connector. This results in the client application having more control over what happens server-side, but you’re still limited by saved searches and the server-side optimizations are limited.
Extract, Transform, Load (ETL)
There are a few solutions to the Splunk ODBC issues, but all of them involve making copies of your data. Where you send your data and in what format is up to you, but make that decision with the software in mind that you plan to use (see Analytics at Scale further down). Of course, some are more elegant than others.
- Use our free Export Everything Add-On for Splunk to transform and export your Splunk data to any supported location in any format using the included search commands or alert actions.
- Leverage the power of SPL to aggregate multiple data sources and lookups to produce the exact results you need to export.
- All of the functionality stays within Splunk, making it accessible to all users and sharing its capabilities.
- Security is finely controlled using 1) passwords in the Splunk Secret Store, 2) permissions that are manageable via the Setup UI, and 3) capabilities required to run each command must be added to the appropriate user roles.
Feel free to contact us with any questions or for support with our apps.
- Use Cribl LogStream as an intermediary input between your Splunk forwarders and indexers. From there, forward as many copies as you like, in any format, to any number of destinations they support.
- Route and filter data, so you don’t incur extra costs against your Splunk license.
- Aggregate events and/or reformat data before forwarding.
- Replay your data from a third-party data store to Splunk if it’s needed later for investigation or audit purposes.
Cribl LogStream is free for up to 5 TB/day of log ingestion. If you’re interested in purchasing Cribl or want deployment help, contact us and we’ll be happy to get you setup. Deductiv is a Cribl partner.
- Use the criblstream search command to send your search results to Cribl LogStream, where you can route and filter them to your heart’s content.
- Use the dbxoutput command from the Splunk App for DB Connect. Of course, this requires a separate SQL database to house your data with tables and a schema already setup.
Once you have the solution setup to export your data out of Splunk (or the Splunk log stream) on a consistent and repeatable basis, you must decide where to send it and in what format. We recommend sending this to an object storage repository like Amazon S3, and will assume that is our destination here for the sake of brevity. If you’re stuck in a datacenter, you should consider looking at MinIO as it provides an S3-compatible interface to access object storage within your datacenter or as a container. As for the file format, JSON is a great place to start because most applications support it or can read it through an adapter.
Going Straight to the Source
If none of the above solutions will work for you, you have a few options left. However, you’ll be completely outside of the Splunk ecosystem and may need to learn, manage, and support new IT infrastructure.
- Dual-feed your data sources at your Splunk forwarders or indexers to a separate data stream (e.g. syslog). This can get funky when your syslog server isn’t available or there are other upstream issues, since your Splunk indexing queue is shared by the routine that writes to disk and the one that forwards to other syslog destinations. If your syslog stream gets backed up, the queue may fill and cause indexing issues.
- If your data comes from a cloud-native system, you can use the messaging pipelines built into you cloud provider’s infrastructure to fork the feed and send your data straight to your object storage buckets.
- Use a secondary logging agent (e.g. Beats, Logstash, etc.) at the data source to parse and deliver the message to the most optimal location for your reporting application. This might be a great solution if you aren’t running Splunk, have no logging infrastructure in place, or have an edge case for data collection (e.g. from a database). Logstash supports a whole host of input and output modules and can convert the data format on the fly, sending to any number of destinations.
Any way you choose, your data will end up outside of Splunk (hopefully) in the ideal object storage location for your analytics software.
Analytics at Scale
If you’ve exported your data into object storage and it’s accessible outside of Splunk, there are a wealth of BI tools to store and/or analyze it. The scalability of a solution will be driven by how many resources can work in parallel on the same task, so you may want to weigh in favor of technologies that parallelize work across multiple nodes for queries as well as ingest (like Splunk does). If you’re using AWS, one important factor to consider is if you want to leverage the capabilities of AWS S3 Select to speed up performance and reduce the financial cost of queries; some solutions leverage it (often referring to it as “S3 Select Pushdown”) and others don’t.
Scuba
Scuba Analytics is used for real-time analytics and can read any JSON data you drop into S3. It uses intuitive drag-and-drop dashboards, and its proprietary engine is incredibly fast. Their software is built by former Facebook engineers and we highly recommend checking it out. Deductiv is a Scuba Analytics partner, so feel free to connect with us if you think it might be a fit for you.
SQL Adapters
Most other tools require a SQL connection, which can be configured by setting up one or more of these applications. There are plenty of tutorials online, so we won’t go into depth here. However, you will need a client-side ODBC or JDBC driver for the software you are connecting to.
- Apache Hive – Produces a catalog of your available data and creates an abstraction layer. Requires a driver interface and an RDBMS-based Metastore (generally MySQL).
- Apache Spark – A unified analytics engine for large-scale data processing, Spark is one of the most versatile frameworks available.
- Trino (Formerly Presto SQL) – An open source distributed query engine for Big Data, it uses a Hive Metastore on the backend.
- AWS Athena + Glue – This is an AWS-specific option. Note that Athena has its own Power BI connector.
Connecting Your BI Tools
Note that Amazon EMR includes Hive, Spark, and Presto. We recommend that you research each option to see which one most closely fits your needs. Once your SQL engine is setup and configured along with your drivers, you can connect to your object storage data with any BI software that supports ODBC or JDBC connections, including:
- Microsoft Power BI
- Tableau
- QlikView
- Looker for Google Cloud Platform
- Domo
Note that you can also connect your data to your lake/warehouse/lakehouse solution of choice such as Databricks, Snowflake, or Dremio, so long as your vendor supports it.
Caveats
Not everyone supports the idea of having multiple copies of your data floating around, and for good reason. Be sure you have governance and retention controls for any data copy locations to comply with your organization’s retention policy. Also be sure you’re securing your data by strictly copying to locations of “least privilege” access, so only those with “need to know” or specific service accounts can read the data. Lastly, having a central data repository and choosing Splunk as a strategy is important to leadership teams in many organizations; however, our role is to enable business and we’d like these tips to help you do just that.
We hope you enjoy our app and this article and will consider sharing them with your people. Be sure to subscribe so you don’t miss the next ones.
Where to Find It
We’re excited to publish Export Everything on Splunkbase for free to all Splunk users, and look forward to the feedback you have. The project is open source and can be found on Github, where you’ll find lots of documentation. Happy exporting!
Hello J.R. Murray,
Well written insights on Spunk Data and its abilities in Self-Service analytics.